No todo el mundo está al tanto del funcionamiento de Google, para los que no lo saben, el buscador determina la posición de una página mediante diferentes señales, una de estas son los links que se dirigen hacia un sitio, y también otros métodos como por ejemplo redirecciones, algo que seguramente han visto al entrar a una página y que rápidamente son dirigidos a otra.
¿Qué tienen que ver las universidades y el viagra?
Si leyeron el párrafo anterior, se darán cuenta que para posicionar un sitio en una búsqueda hay que conseguir enlaces o links hacia el sitio que quieren que aparezca en las primeras posiciones de los resultados de Google, y es aquí donde las universidades y muchos otros sitios son víctimas de hackers que aplican técnicas de SEO (optimización para motores de búsqueda) para ganar terreno en los resultados del buscador. El viagra es un negocio muy redituable, y es por eso que muchos de los sitios que son víctimas de estos ataques son utilizados para posicionar paginas relacionadas con este producto.
Ojo, el viagra no es el único, se puede encontrar de todo, incluso links para posicionar una página de videos sexuales de famosos, alquileres baratos, y todo lo que se les pueda ocurrir, y aún más cosas que no se imaginan.
¿Por qué universidades?
Si bien es tema de discusión, se cree que los links provenientes de sitios con dominios .edu (instituciones educativas) o .gov (instituciones gubernamentales) tienen más peso que los provenientes de otros sitios. De todos modos, todos los sitios son atacados por igual, pero obviamente estas instituciones son el blanco más deseado, y aparentemente son más vulnerables que lo esperado, al menos por mi.
Lista de ejemplo de instituciones vulneradas
Entre las víctimas de estos ataques se encuentran las siguientes instituciones:
- Facultad de Ciencias Médicas de la Universidad Nacional del Litoral
- Portal Educativo de La Rioja (IDUKAY)
- Universidad Nacional de Mar del Plata
- Facultad de Psicología de la Universidad Nacional de Córdoba
- Facultad de Turismo de la Universidad Nacional de Comahue
- Facultad de Ciencias de la Salud de la Universidad Nacional de Entre Ríos
- Universidad de San Pablo – Tucumán
- Centro de Investigación Cinematográfica
- Colegio Provincial Técnico Nº 748
- Facultad Regional Santa Fe de la Universidad Tecnologica Nacional
La lista sigue, y mucho, además hay que considerar que también hay sitios hackeados que fueron utilizados para fines diferentes.

Ejemplo de una pagina de una universidad
¿Cómo encontrar los sitios comprometidos?
El método que utilicé para hacerlo es “artesanal”, ya que en realidad se utiliza a Google como herramienta, sí, el mismo Google que los hackers intentan burlar.
Esta es la búsqueda realizada para encontrar los sitios:
https://www.google.com/search?q=inurl:.edu.ar+viagra
Pueden cambiar “viagra” por otras palabras usadas comúnmente, por ejemplo: cialis, rolex, etcétera.
Entro al sitio y parece limpio
Ajá, es la idea, campeón. Hay muchas técnicas para esconder los enlaces, en las más simple se esconde dentro del contenido del sitio, y no es posible verlo a simple vista, pero si se pueden ver al urgar el código fuente de la pagina, para verlo puede ir en su navegador a “Ver código de fuente” o CTRL+U en Chrome.
Ok, mire el código de fuente y no hay nada raro. Bien, Sherlock. La otra técnica para ocultar información es un poco más compleja, comúnmente conocida como Cloaking en el rubro del posicionamiento, y se basa en mostrar contenido diferente según quien mira la pagina, de éste modo el sitio que ve Google es diferente al que ven los usuarios.
¿Cómo se si están usando Cloaking?
Hay una forma difícil y efectiva, y otra simple pero no tan efectiva, les voy a enseñar la forma simple, y en verdad es muy simple, solo basta con realizar la búsqueda que compartimos más arriba y en vez de clickear en el titulo del resultado, hacer clic en el caret o triangulo que se encuentra al final de la URL del mismo, se van a desplegar una o dos opciones, ustedes deben seleccionar la que dice “Cached”, y de ese modo pueden ver el sitio como lo vió Google cuando entró a ver el contenido del sitio.

Ver un sitio como lo ve Google
¿Qué importancia tiene esto?
Bueno, la lista es larga pero que tengan acceso para agregar estos enlaces muchas veces significa que también lo tienen para acceder a información privada de los integrantes (alumnos, docentes) de la institución.
Ojo, eso no es lo peor, muchos de estos sitios redireccionan a paginas que pueden explotar vulnerabilidades en su navegador o plugins (Flash, Java), y ahí la cosa se torna más peligrosa, ya que si el atacante consigue acceso a su PC, bueno, ustedes sabrán el riesgo que eso implica.
Phishing, otras veces se utilizan estos ataques para crear paginas que son utilizadas en esos mails falsos que llegan diciendo ser alguien que no son, en general personificando bancos e instituciones financieras, y en las que al acceder a un enlace nos piden información o instalan algo en nuestra PC.
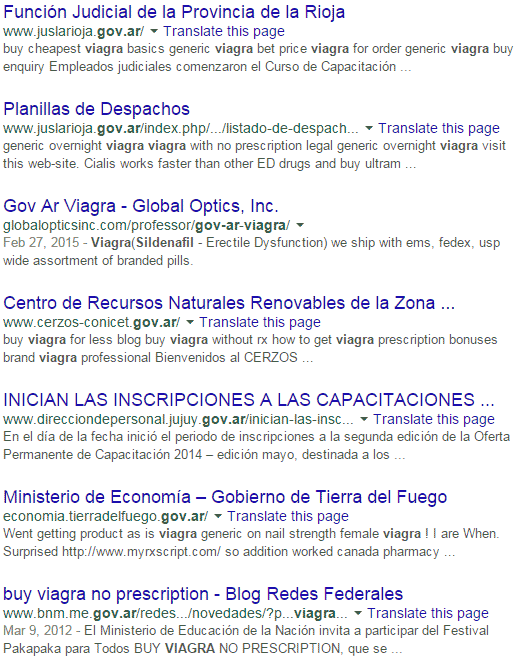
¿Los políticos consumen viagra?
Que pregunta, lo dejo a su criterio:
https://www.google.com/search?q=inurl:.gov.ar+viagra

Apaa, pero mirá vos!
Una aclaración final
Mas de uno en este momento debe estar odiando a aquellos que hacen SEO, pero tengan en cuenta que estas son técnicas conocidas como BlackHat SEO, y no son aprobadas por la mayoría de la comunidad, y menos que menos por Google, que se encuentra activamente luchando contra estos trucos para burlar sus algoritmos. Si Google lo encuentra usando estas estrategias, tarde o temprano van a ser penalizados, lo malo es que penaliza tanto al sitio donde se encuentran los enlaces como al sitio al cual se dirigen éstos.